不停机数据库迁移
已上线服务若停机,轻则影响使用者的心情,重则会造成无法估计的损失。试想如果淘宝停机五分钟,那会损失多少真金白银。但数据库表结构却不可能在一开始就设计的十分完美,需要不断迁移,不断迭代。本文尝试分析数据库迁移时可能造成的停机原因,并以 Rails + PostgreSQL 为例,提出不停机的数据库迁移方案 (Zero downtime migrations)。
为什么会停机?
在做数据库迁移时,为什么会造成停机?总的来说有两个原因:
- 应用程序代码不能同时兼容迁移前/后的数据库
- 迁移导致数据库锁表
分别来看一下如何避免这两种情况的发生:
代码不兼容迁移前后的数据库
如果不停机,在迁移脚本运行后,新应用程序部署成功前,有一段时间,当前代码要运行在新数据库表结构上,如果不做向前兼容,会因为表结构不匹配而导致应用程序挂掉。解决这种问题的方法很简单,只要记住这句话:代码需要能同时运行在迁移前/后的数据库上。通常分以下三步走,来保证这一点:
- 修改代码,保证代码能兼容迁移后的数据库
- 运行迁移脚本
- 删除兼容的代码,保证只运行在新数据库上
举个例子来说明这个问题:
从表中删除一列
下面是一段 Rails 数据迁移代码,其作用是删除数据表 users 中的 status 列。
class RemoveStatusFromUsers < ActiveRecord::Migration
def change
remove_column :users, :status, :string
end
end
可以保证一点,status 列没有被使用,也不是其它表的外键。乍一看是非常安全的,单从数据库方面考虑,删除列是安全的。但若访问应用,会得到如下异常:
PGError: ERROR: column "status" does not exist
原因是 ActiveRecord 会提前读取并缓存表的所有列,当你删除 status 后,新数据保存时在数据库中找不到 status 列。解决方法当然很简单,像上面一样分三步走:
a. 兼容迁移后的数据库,可通过忽略 status 字段来实现。
# For Rails 5+
class User < ApplicationRecord
self.ignored_columns = ["status"]
end
# For Rails < 5
class User < ActiveRecord::Base
def self.columns
super.reject { |c| c.name == "status" }
end
end
b. 运行迁移脚本
class RemoveStatusFromUsers < ActiveRecord::Migration
def change
remove_column :users, :status, :string
end
end
c. 删除兼容的代码
class User < ActiveRecord::Base
end
通过三次部署来实现不停机删除表中的一列。
迁移导致数据库锁表
数据库的迁移操作主要包括三个方面:
- 数据库操作:重命名数据库 (不在本文讨论范围)
- 表的操作:增/删/重命名表
- 列的操作:增/删/重命名列,更改类型,添加引用/索引/限制等
下表总结了 19 中常见的数据库迁移操作:
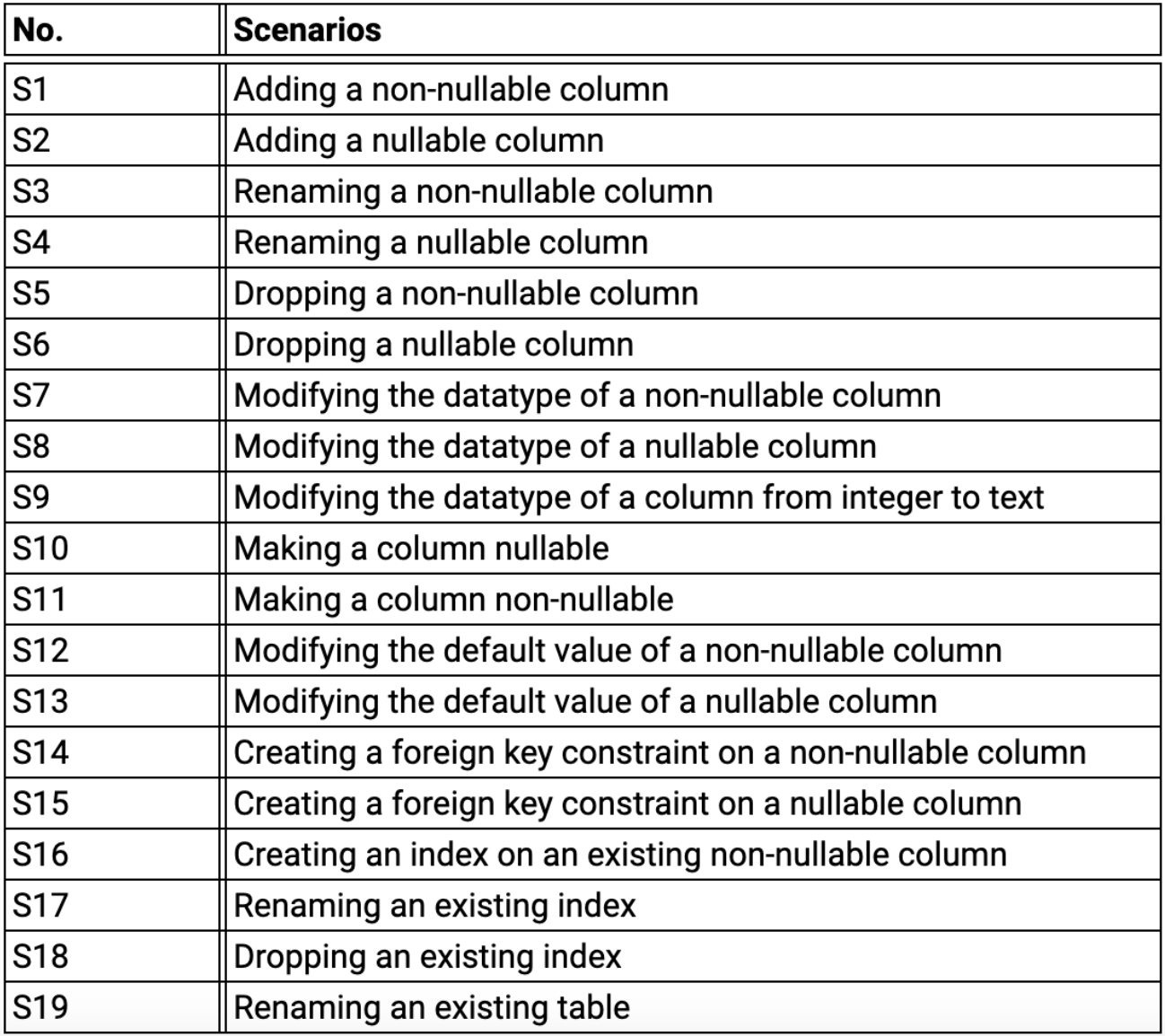
这 19 种操作在 MySQL 和 PostgreSQL 上的测试结果如下表所示:
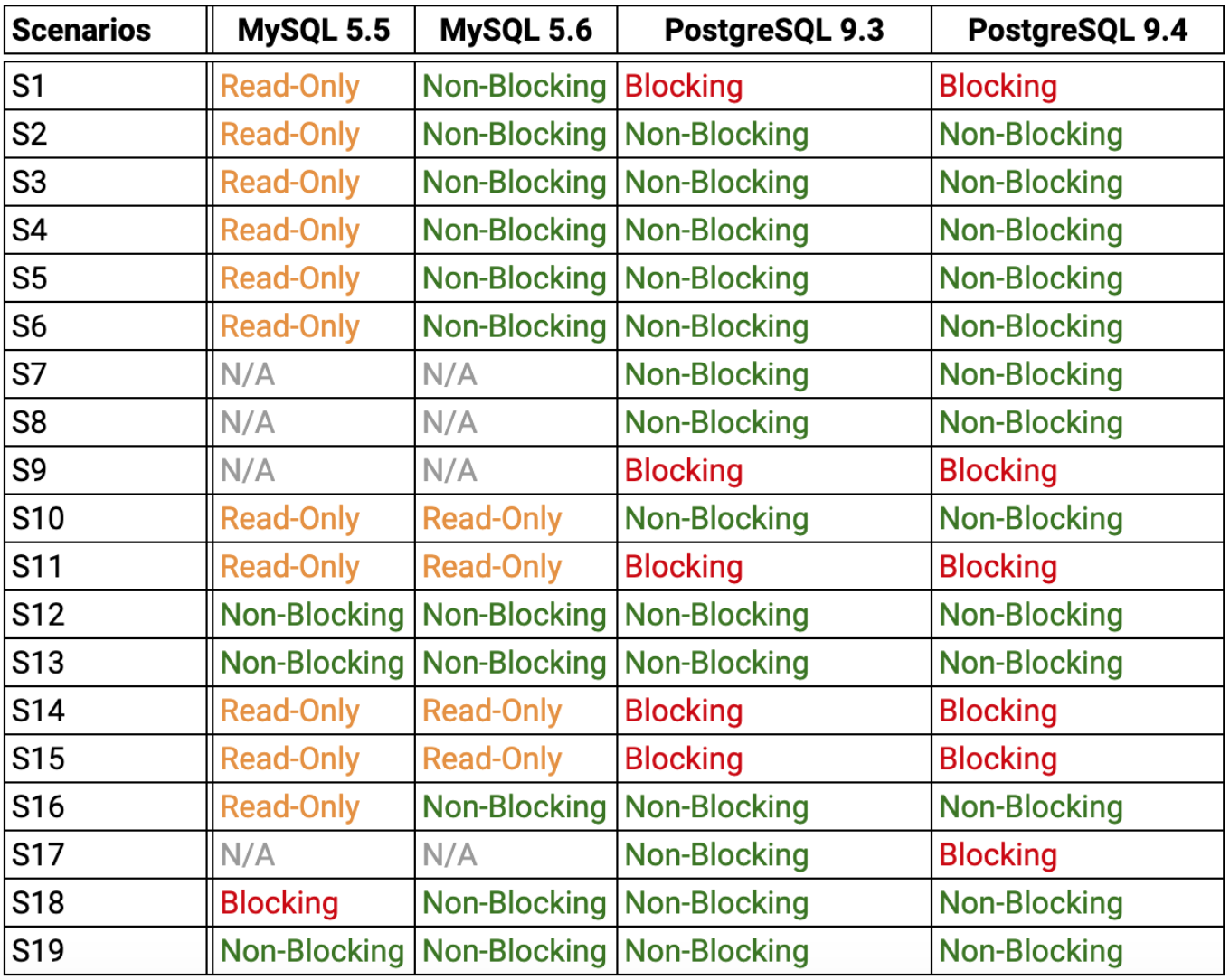
整理一下,从数据库层面来说,造成 PostgreSQL 锁表的情况如下:
- 添加非空列/默认值不为空列
- 改变某列的类型
- 添加/重命名索引
- 添加外键/限制
针对这几种情况,我们逐一解决:
添加一列,默认值不为空
不好的做法
添加一列同时设置默认值不为空时,会造成锁表。
class AddSomeColumnToUsers < ActiveRecord::Migration[5.2]
def change
add_column :users, :some_column, default: "default_value"
end
end
推荐的做法
先添加一列,不要默认值,再设置默认值,能避免锁表。
class AddSomeColumnToUsers < ActiveRecord::Migration[5.2]
def up
add_column :users, :some_column, :text
change_column_default :users, :some_column, "default_value"
end
def down
remove_column :users, :some_column
end
end
这样设置的默认值只会对新数据有效,如果数据库中已存在没有默认值的行,需要另起一个迁移脚本,写默认值到旧数据中,写操作不要和设置默认值的操作放在一个文件。确保这种写操作不要处于事务中,在 Rails 中,可用 disable_ddl_transaction! 来实现,如下所示:
class BackfillSomeColumn < ActiveRecord::Migration[5.2]
disable_ddl_transaction!
def change
# Rails 5+
User.in_batches.update_all some_column: "default_value"
# Rails < 5
User.find_in_batches do |records|
User.where(id: records.map(&:id)).update_all some_column: "default_value"
end
end
end
改变某列的类型
不同的数据类型会改变数据库底层存储结构,会导致锁表。安全的方法分以下几步:
- 创建一个新列,设置数据类型为你想要的类型
- 同时写新/旧两列
- 把老数据填到新列中
- 开始从新列读数据
- 停止在旧列中写数据
- 删掉旧列
tips: Postgres 9.1+ 版本中,把数据类型从 varchar 改成 text 是安全的。
添加索引
不好的做法
给存在的数据加索引时会锁表:
class IndexUsersOnEmail < ActiveRecord::Migration
def change
add_index :users, :email
end
end
推荐的做法
并行加索引,并且不把添加索引的脚本放在事物中能阻止锁表
class IndexUsersOnEmail < ActiveRecord::Migration
disable_ddl_transaction!
def change
add_index :users, :email, algorithm: :concurrently
end
end
添加外键/限制
添加外键的方法:
class AddSomeReferenceToUsers < ActiveRecord::Migration[5.2]
disable_ddl_transaction!
def change
add_reference :users, :reference, index: false
add_index :users, :reference_id, algorithm: :concurrently
end
end
除了数据库层面,从 Rails 方面,也有一些可能造成停机的操作:
- 循环
- 把多种数据库操作混在一个事务中
- 重命名表
循环
不好的做法
以下循环可能一次读入成千上万的数据到内存中,拖垮机器:
class BackportPublishedDefaultOnPosts < ActiveRecord::Migration
def up
Post.unscoped.each do |post|
post.update_attribute(published: true)
end
end
end
推荐的做法
使用 find_each 分批更新:
class BackportPublishedDefaultOnPosts < ActiveRecord::Migration
def up
Post.unscoped.find_each do |post|
post.update_attribute(published: true)
end
end
end
把多种数据库操作混在一个事务中
不好的做法
把添加列,更新列和添加索引放在同一个事务中运行,存在性能问题,不安全。
class AddPublishedToPosts < ActiveRecord::Migration
def change
add_column :posts, :published, :boolean
Post.unscoped.update_all(published: true)
add_index :posts, :published
end
end
推荐的做法
每一类操作使用一个单独的事务,添加索引不放在事务中。
# 1
class AddPublishedToPosts < ActiveRecord::Migration
def change
add_column :posts, :published, :boolean
end
end
# 2
class BackportPublishedOnPosts < ActiveRecord::Migration
def up
Post.unscoped.update_all(published: true)
end
end
# 3
class IndexPublishedOnPosts < ActiveRecord::Migration
disable_ddl_transaction!
def change
add_index :posts, :published, algorithm: :concurrently
end
end
重命名表
重命名表可以用类似改变列类型的思路来实现。在 Postgres 这种关系型数据库中,有视图的概念,视图是构建在表之上的逻辑结构。幸运的是,插入或者删除视图时,会同时更新底层的表。用视图可以简化重命名表的操作。
a. 创建视图
class CreateAuthorsView < ActiveRecord::Migration[5.2]
def up
execute 'CREATE VIEW authors AS SELECT * FROM persons'
end
def down
execute 'DROP VIEW authors'
end
end
b. 修改代码,使用新名称 authors 代替 persons
+ AuthorModel
+ AuthorController
+ AuthorService
- PersonModel
- PersonController
- PersonService
c. 重命名表名,并删掉旧视图
class RenameTable < ActiveRecord::Migration[5.2]
def up
execute "RENAME TABLE `authors` TO `authors_old_view`, `persons` to `authors`";
execute "DROP VIEW `authors_old_view`";
end
def down
...
end
end
大功告成!
其中 RENAME TABLE 命令可同时重命名多个表,但是数据库保证其为原子操作。
不停机迁移不是银弹
正如上文所示,要保证应用不停机,要想清楚迁移后的数据库结构,需要修改代码做兼容,并按照严格的顺序部署应用,执行迁移脚本。如果数据库表结构变化比较大,这种工作会变得繁重并容易出错,在这种情况下,也许停机发布是一个不错的选择。Airbnb 就曾有过停机发布的做法。
停机发布需要注意以下几点:
- 虽然是停机发布,但是也要做好足够的准备工作
- 提前一个月或者更长的时间通知用户
- 选择一个恰当的时机发布
总结
不停机数据库迁移需要保证两点:1. 代码需要兼容迁移后的数据库,2. 迁移脚本保证不锁表。为了做好这两点,需要按一定顺序做迁移,并把锁表的操作转化成不锁表的操作。除了数据库本身的锁表,还需要关注框架引入的问题。
引用
- Zero downtime migrations in rails
- Zero downtime migrations
- Paper: Zero-Downtime SQL Database Schema Evolution for Continuous Deployment
- Renaming tables with zero downtime
- Zero downtime with activerecord
如果你喜欢这篇文章,欢迎赞赏作者以示鼓励

